
In the ever-evolving landscape of software development, efficient CI/CD pipelines are crucial for delivering high-quality code. These pipelines often involve the configuration of jobs that automate various tasks, and one common challenge is the manipulation of variables across these jobs. In this article, we'll explore a specific job configuration and delve into the significance of self-referencing variables within it.
Why self-referencing variables?
In DataOps CI/CD, self-referencing variables can be useful in various scenarios to enhance the flexibility and maintainability of your pipeline configuration. Self-referencing variables allow you to refer to the value of a variable within its own definition. Here are some possible use-cases:
- Dynamic Variable Generation
- You may want to generate variables dynamically based on some conditions or values calculated during the pipeline execution. Self-referencing variables enable you to use the value of an existing variable to construct a new one.
- Branch-specific Configuration:
- You might have different configuration settings for various branches. Self-referencing variables can be used to define branch-specific settings without duplicating the entire configuration block.
- Recursive Definitions:
- Self-referencing variables can be used to create recursive definitions where a variable refers to itself. This can be handy for iterative processes or dynamic updates.
- Path Definitions:
- Define path variables based on a root directory, allowing for easy adjustments and maintenance.
- Reusing Variables in Job Scripts:
- You can use self-referencing variables to pass a consistent value across multiple jobs or stages in a pipeline
Example Configuration:
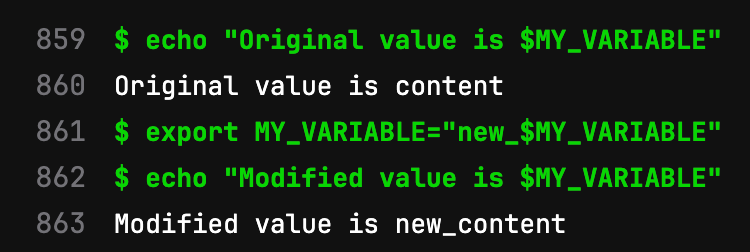
The following job demonstrates the correct usage of self-referencing variables by redefining them within the `script` section or the `before_script` section, rather than modifying them under the `variables` key.
"Example Job":
extends:
- .agent_tag
stage: "test"
image: $DATAOPS_PYTHON3_RUNNER_IMAGE
variables:
# MY_VARIABLE: 'content' #defined in the -ci.yml file or as a CI/CD variable or inherited from a previous job
### SHOWCASE not working examples:
# MY_VARIABLE: 'new_${MY_VARIABLE}' # does not work when self-referencing a variable
# MY_VARIABLE: 'new_$MY_VARIABLE' # does not work when self-referencing a variable
# MY_VARIABLE: "new_{{MY_VARIABLE}}" # does not work when self-referencing a variable
###
script:
- /dataops
- echo "Original value is $MY_VARIABLE"
# - export MY_VARIABLE="new_$MY_VARIABLE"
# - echo "Modified value is $MY_VARIABLE"
icon: ${PYTHON_ICON}The successful job produces an output resembling the following example:
Understanding and mastering the intricacies of CI/CD pipelines, especially when it comes to job configurations and variable manipulation, is essential for building robust and efficient development workflows. The "Example Job" configuration provides a concrete example of how self-referencing variables can be both challenging and crucial for achieving the desired outcomes. By acknowledging and addressing these challenges, developers can enhance the reliability and maintainability of their CI/CD pipelines, contributing to a smoother and more streamlined software development process.