

In the realm of continuous integration and continuous deployment (CI/CD), tracking failures and analysing them is crucial for maintaining the health and efficiency of data product development processes. DataOps CI/CD pipelines offer a powerful framework for automating these processes, but extending them with custom solutions can provide even deeper insights. One such custom solution involves integrating failure tracking directly into the pipeline, allowing teams to efficiently monitor and address issues as they arise.
The Custom Solution:
To address the need for automated failure tracking, we propose a custom solution that seamlessly integrates with DataOps CI/CD pipelines. This solution leverages an after_script hook in the SOLE job added in the -ci.yml configuration file to execute a Python script (record_failures.py) whenever a job fails. The Python script then connects to a Snowflake database and records details about the failed job into a dedicated table.
The Code:
-ci.yml
Set Up Snowflake:
after_script:
- >
if [ $CI_JOB_STATUS == "failed" ]; then
export DATAOPS_SOURCE_FILE=$CI_PROJECT_DIR/env.sh
source $DATAOPS_SOURCE_FILE
python3 $CI_PROJECT_DIR/scripts/record_failures.py
echo "run record_failures.py script"
else
exit 0
fi
record_failures.py
import snowflake.connector
import os
import sys
job_status = os.getenv('CI_JOB_STATUS')
job_name = os.getenv('CI_JOB_NAME')
commit_ref_name = os.getenv('CI_COMMIT_REF_NAME')
job_stage = os.getenv('CI_JOB_STAGE')
pipeline_id = os.getenv('CI_PIPELINE_ID')
job_url = os.getenv('CI_JOB_URL')
database = os.getenv('DATABASE')
user = os.getenv('DATAOPS_SOLE_USERNAME')
password = os.getenv('DATAOPS_SOLE_PASSWORD')
account = os.getenv('DATAOPS_SOLE_ACCOUNT')
warehouse = os.getenv('DATAOPS_SOLE_WAREHOUSE')
session = snowflake.connector.connect(
user=user,
password=password,
account=account
)
cursor = session.cursor()
try:
cursor.execute("USE WAREHOUSE " + warehouse)
cursor.execute("CREATE DATABASE IF NOT EXISTS " + database)
cursor.execute("CREATE SCHEMA IF NOT EXISTS " + database + ".FAILURES")
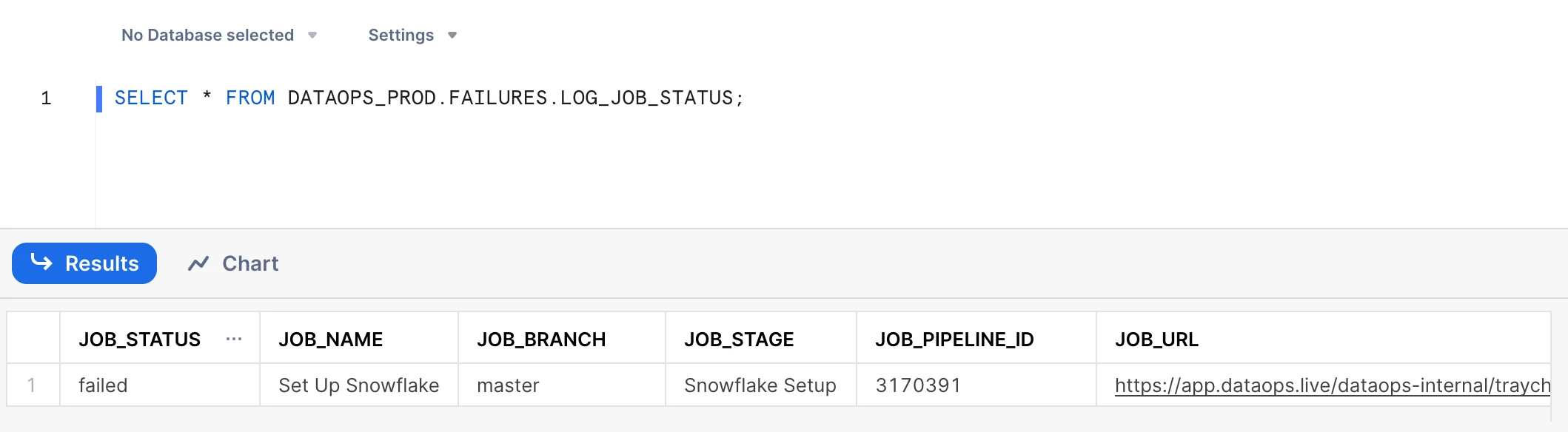
cursor.execute("""CREATE TABLE IF NOT EXISTS """ + database + """.FAILURES.LOG_JOB_STATUS (
JOB_STATUS VARCHAR(1000),
JOB_NAME VARCHAR(1000),
JOB_BRANCH VARCHAR(1000),
JOB_STAGE VARCHAR(1000),
JOB_PIPELINE_ID VARCHAR(1000),
JOB_URL VARCHAR(1000),
DATE_TIME TIMESTAMP_TZ(9))""")
query = """
INSERT INTO {database}.FAILURES.LOG_JOB_STATUS (
JOB_STATUS,
JOB_NAME,
JOB_BRANCH,
JOB_STAGE,
JOB_PIPELINE_ID,
JOB_URL,
DATE_TIME
) VALUES (
'{job_status}',
'{job_name}',
'{commit_ref_name}',
'{job_stage}',
'{pipeline_id}',
'{job_url}',
convert_timezone('Europe/London', current_timestamp())
)
""".format(
database=database,
job_status=job_status,
job_name=job_name,
commit_ref_name=commit_ref_name,
job_stage=job_stage,
pipeline_id=pipeline_id,
job_url=job_url
)
cursor.execute(query)
except Exception as Ex:
print(Ex)
finally:
cursor.close()
session.close()
The record_failures.py script begins by importing the necessary libraries and retrieving environment variables related to the failed job, such as job status, name, branch, stage, pipeline ID, and URL. It then establishes a connection to the Snowflake database and creates a table if it does not already exist. Subsequently, it constructs an SQL query to insert the job details into the table, including the current timestamp converted to the desired timezone.
Why It's Useful:
This custom solution offers several benefits to development teams:
- Automatically recording details of failed jobs provides immediate visibility into issues within CI/CD pipelines, facilitating prompt investigation and resolution.
- Historical analysis of recorded data enables teams to identify trends and patterns in failures over time, aiding in process improvements and optimisation efforts.
- Storing failure data in a centralised Snowflake database creates a single source of truth for tracking and analyzing failures across all projects and pipelines.
- The solution is customisable and extensible, allowing for easy adaptation to capture additional metadata or integrate with other tools and platforms based on specific development environment requirements.
How It Works:
When a SOLE job within a DataOps CI/CD pipeline fails, the after_script hook triggers the execution of the record_failures.py script. This script retrieves relevant job details and inserts them into the Snowflake database. As a result, teams have real-time access to comprehensive failure logs, empowering them to diagnose issues promptly and make informed decisions.
Conclusion:
Incorporating automated failure tracking into DataOps CI/CD pipelines enhances visibility, accountability, and efficiency within data product development processes. By leveraging a custom solution that integrates seamlessly with existing pipelines, teams can proactively monitor failures, analyse trends, and continuously improve their workflows. With the power of data-driven insights, development teams can optimise their CI/CD practices and deliver high-quality data products with greater speed and reliability.