

Hi DataOps.live User,
Welcome to the August newsletter! Find out how our latest developments enhance your DataOps experience. Save time investigating Snowflake spend. Make the most of DDE. Enhance reliability and fault tolerance. And more. Read on.
Enhancements in Spendview for Snowflake
Compute is often the top cost area for optimization related to a Snowflake Warehouse, where the most common problems are query performance and idle warehouses.
Spendview for Snowflake brings awareness to business stakeholders and data team leads to understand their current resource usage. Spendview provides big saving opportunities in a matter of clicks as it empowers your data team with self-service Snowflake consumption and spending metrics.
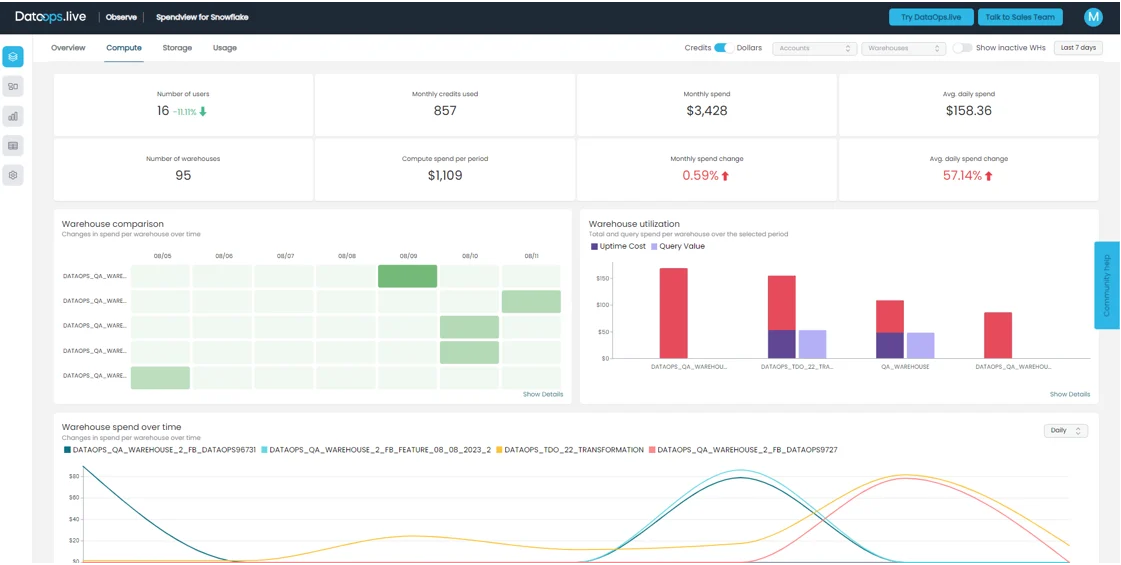
Sign up now for our live webinar on optimizing your Snowflake spend and join DataOps.live and XponentL Data discussion on how you can perfect your budget by following best practices and cost-saving strategies.
Optimize the Potential of DataOps Development with dbt
Make the most of the DataOps Development Environment (DDE) by using the latest dbt versions for better production efficiency. DDE is most effective when used with the recent dbt versions, which significantly boosts the development speed.
In DDE, specify the version by setting the DATAOPS_FEATURE_MATE_DBT_VERSION environment variable, for example, DATAOPS_FEATURE_MATE_DBT_VERSION=1.4. Read more.... In the DataOps pipeline, set the variable in your project’s variables.yml file. Sign up for the DDE private preview by reaching out to ours Support team.
Enhancements in SOLE Generator
Managing your existing Snowflake databases through the DataOps.live platform just got a bit easier. Besides supporting database, function, procedure, schema, table, and task, we now also support sequence, tag, stream, and file format.
Start using the SOLE Generator CLI (Command-line Interface) tool that helps you generate a YAML configuration for SOLE objects.
Community
#TrueDataOps Podcast Season 2 is here! Join us with our special guest, Bob Mugila, formerly the Chief Executive Officer of Snowflake. We will cover his new book, The DataPreneurs (https://www.thedatapreneurs.com/), the new age of AI, and all things Data related! Make sure to add it to your calendar. You do not want to miss this episode!

Academy
The latest course - Fundamentals of DataOps.live - just went live at our Academy. In this course, we go step by step through the process of ingesting a new data source using our Stage Ingestion Orchestrator. Topics covered include creating multiple objects with SOLE, autogenerating sources from ingestion tables, creating MATE jobs to run only specified models, creating a new pipeline -ci.yml file, and more. Enroll today!
Did You Know?
…that you can incorporate a fallback job that retries your main job again but with a different container image or with alternative configuration adjustments.
By incorporating a fallback job into a pipeline, developers and data engineers can enhance the reliability, robustness, and fault tolerance of the system.
Read more at Create Fallback Jobs

That’s all for now. Until next time,
- the DataOps.live Product Team
